GPT Image 2AI 提示词
DeepSeek V3 vs V4: Ultimate Transformer Blueprint
Generate a crisp side-by-side infographic comparing DeepSeek V3 and V4 Transformer architectures, perfect for presentations and tech analysis.
提示词 · EN
type
并排 AI 架构对比信息图style
简洁的技术图表,白色背景,细黑色轮廓,圆角矩形,虚线标注框,颜色编码高亮,演示文稿风格,矢量信息图canvas
aspect_ratio
2:1resolution
宽横向title_row
left_title
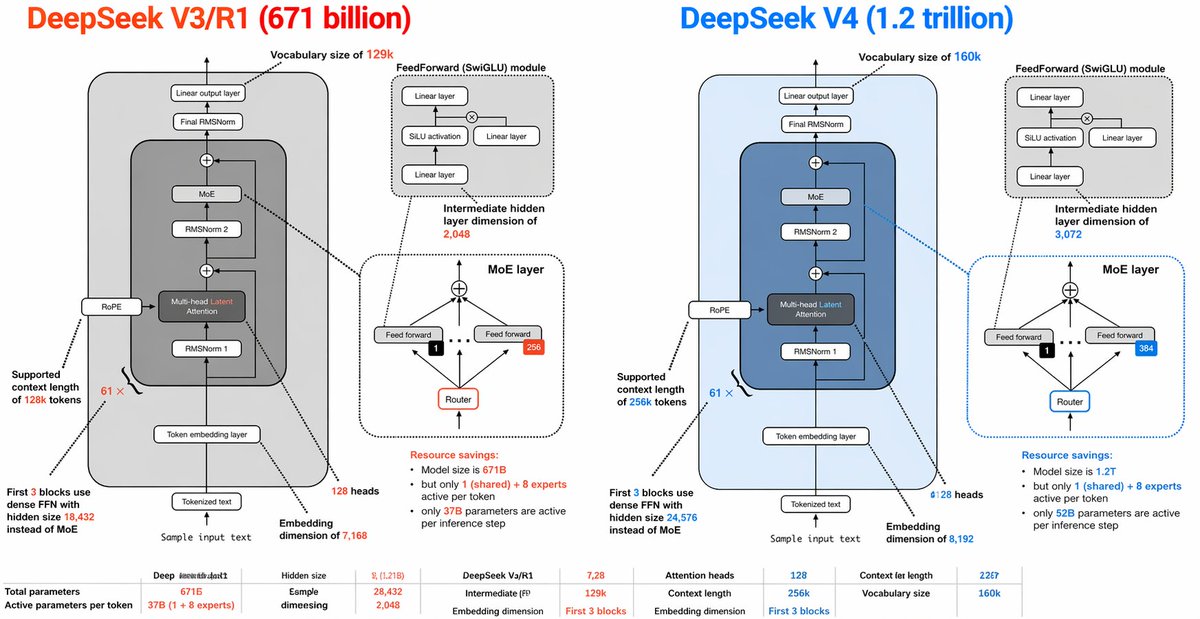
DeepSeek V3/R1 (6710 亿参数)right_title
DeepSeek V4 (1.2 万亿参数)left_title_color
亮橙红色right_title_color
亮蓝色layout
columns
2sections
item 1
title
DeepSeek V3/R1 (6710 亿参数)position
左半部分count
9labels
item 1
词汇表大小 129kitem 2
FeedForward (SwiGLU) 模块item 3
中间隐藏层维度 2,048item 4
MoE 层item 5
支持 128k token 上下文长度item 6
前 3 个块使用隐藏大小为 18,432 的密集 FFN 而非 MoEitem 7
示例文本输入item 8
嵌入维度 7,168item 9
128 个注意力头item 2
title
DeepSeek V4 (1.2 万亿参数)position
右半部分count
9labels
item 1
词汇表大小 160kitem 2
FeedForward (SwiGLU) 模块item 3
中间隐藏层维度 3,072item 4
MoE 层item 5
支持 256k token 上下文长度item 6
前 3 个块使用隐藏大小为 24,576 的密集 FFN 而非 MoEitem 7
示例文本输入item 8
嵌入维度 8,192item 9
128 个注意力头item 3
title
底部对比表position
底部全宽count
10labels
item 1
总参数量item 2
每个 token 的活跃参数量item 3
隐藏层大小item 4
示例维度item 5
DeepSeek V3/R1item 6
中间层 (FF)item 7
注意力头item 8
上下文长度item 9
嵌入维度item 10
词汇表大小left_panel
background
浅灰色圆角矩形main_stack
count
8blocks
item 1
Token 化文本item 2
Token 嵌入层item 3
RMSNorm 1item 4
多头潜在注意力 (MLA)item 5
RMSNorm 2item 6
MoEitem 7
最终 RMSNormitem 8
线性输出层side_module
RoPE 连接到左侧的注意力块attention_block
label
多头潜在注意力 (MLA)accent
Latent 一词使用橙红色文字feedforward_inset
title
FeedForward (SwiGLU) 模块count
4blocks
item 1
线性层item 2
SiLU 激活函数item 3
线性层item 4
线性层diagram
两个分支相乘,然后进行投影moe_inset
title
MoE 层count
5blocks
item 1
顶部组合节点item 2
前馈网络item 3
前馈网络item 4
路由item 5
专家计数徽章 256details
带有 1 个选中专家的小黑方块,箭头指向专家,虚线分隔符annotations
vocab
词汇表大小 129kff_dim
中间隐藏层维度 2,048context
支持 128k token 上下文长度dense_first_blocks
前 3 个块使用隐藏大小为 18,432 的密集 FFN 而非 MoEresource_savings
资源节省:模型大小为 671B,但每个 token 仅激活 1 个(共享)+ 8 个专家;每次推理步骤仅激活 37B 参数bottom_stats
count
10items
item 1
总参数量:671Bitem 2
每个 token 活跃参数:37B (1 + 8 个专家)item 3
隐藏层大小:7,128item 4
示例维度:28,432item 5
中间层 (FF):2,048item 6
注意力头:128item 7
上下文长度:128kitem 8
嵌入维度:前 3 个块item 9
上下文长度:22G7item 10
词汇表大小:129kright_panel
background
浅蓝色圆角矩形main_stack
count
8blocks
item 1
Token 化文本item 2
Token 嵌入层item 3
RMSNorm 1item 4
多头潜在注意力 (MLA)item 5
RMSNorm 2item 6
MoEitem 7
最终 RMSNormitem 8
线性输出层side_module
RoPE 连接到左侧的注意力块attention_block
label
多头潜在注意力 (MLA)accent
Latent 一词使用蓝色文字feedforward_inset
title
FeedForward (SwiGLU) 模块count
4blocks
item 1
线性层item 2
SiLU 激活函数item 3
线性层item 4
线性层diagram
与左侧面板结构相同moe_inset
title
MoE 层count
5blocks
item 1
顶部组合节点item 2
前馈网络item 3
前馈网络item 4
路由item 5
专家计数徽章 384details
带有 1 个选中专家的小黑方块,箭头指向专家,虚线分隔符,蓝色边框强调annotations
vocab
词汇表大小 160kff_dim
中间隐藏层维度 3,072context
支持 256k token 上下文长度dense_first_blocks
前 3 个块使用隐藏大小为 24,576 的密集 FFN 而非 MoEresource_savings
资源节省:模型大小为 1.2T,但每个 token 仅激活 1 个(共享)+ 8 个专家;每次推理步骤仅激活 52B 参数bottom_stats
count
10items
item 1
总参数量:1.2Titem 2
每个 token 活跃参数:52B (1 + 8 个专家)item 3
隐藏层大小:7,2Bitem 4
示例维度:28,432item 5
中间层 (FF):3,072item 6
注意力头:128item 7
上下文长度:256kitem 8
嵌入维度:前 3 个块item 9
上下文长度:22G7item 10
词汇表大小:160kglobal_notes
创建一个高度详细的 Transformer 架构对比图,采用镜像布局。每一半包含一个大型模型堆栈图和 2 个插图:1 个前馈模块和 1 个 MoE 层。在块之间使用箭头,添加微小的技术标签,并使用连接线将标签指向相关组件。保持排版紧凑且具有演示文稿感,所有 V3/R1 的强调使用橙红色,所有 V4 的强调使用蓝色。在底部包含一行跨越全宽的紧凑指标表。保留略显不完美的手绘信息图风格,文字较小且标注密集。关于这个提示词
Generate a crisp side-by-side infographic comparing DeepSeek V3 and V4 Transformer architectures, perfect for presentations and tech analysis. 它更适合作为 GPT Image 2 的概念艺术起点:先保留画面结构、主体关系和风格约束,再替换成你的品牌、人物或场景。
这条提示词使用结构化 JSON 组织信息,包含 type、style、canvas、title row、layout、left panel、right panel 等字段。保留这种层级能让模型更清楚地区分画面主题、布局、界面元素和细节约束。
使用时建议先小幅修改主体、场景、镜头和色调,再生成多个版本对比构图与细节。这样页面内容对用户有实际帮助,也避免把模型名或标签机械堆在正文里。
如何使用这个提示词
- Copy the provided JSON prompt from the page.
- Choose an AI model capable of interpreting structured infographic prompts (e.g., a custom GPT or image generation tool).
- Adjust any labels, color codes, or dimensions to suit your content needs.
- Submit the prompt and generate your side-by-side architecture infographic.


